
Delivering Large-Scale Platform Reliability – Roblox Blog
[ad_1]
Running any scalable distributed system demands a commitment to reliability, to ensure consumers have what they require when they have to have it. The dependencies could be relatively intricate, particularly with a system as large as Roblox. Developing reputable providers usually means that, regardless of the complexity and standing of dependencies, any offered support will not be interrupted (i.e. very obtainable), will run bug-no cost (i.e. high quality) and with out errors (i.e. fault tolerance).
Why Reliability Issues
Our Account Id group is dedicated to reaching larger dependability, due to the fact the compliance products and services we created are main factors to the system. Damaged compliance can have significant repercussions. The price tag of blocking Roblox’s natural operation is really higher, with additional methods needed to recuperate just after a failure and a weakened person encounter.
The standard method to trustworthiness focuses primarily on availability, but in some circumstances conditions are combined and misused. Most measurements for availability just evaluate regardless of whether products and services are up and working, though facets this sort of as partition tolerance and regularity are from time to time forgotten or misunderstood.
In accordance with the CAP theorem, any distributed program can only assure two out of these 3 elements, so our compliance solutions sacrifice some regularity in purchase to be extremely obtainable and partition-tolerant. However, our providers sacrificed minimal and identified mechanisms to obtain superior consistency with acceptable architectural variations discussed under.
The system to reach increased trustworthiness is iterative, with restricted measurement matching continual do the job in buy to avoid, uncover, detect and repair problems prior to incidents take place. Our staff determined strong worth in the adhering to procedures:
- Right measurement – Build entire observability around how good quality is delivered to prospects and how dependencies deliver high quality to us.
- Proactive anticipation – Execute pursuits these kinds of as architectural testimonials and dependency possibility assessments.
- Prioritize correction – Carry higher focus to incident report resolution for the company and dependencies that are connected to our provider.
Developing better reliability demands a culture of top quality. Our group was previously investing in general performance-driven improvement and is aware the success of a procedure depends on its adoption. The crew adopted this procedure in full and utilized the procedures as a standard. The subsequent diagram highlights the factors of the process:
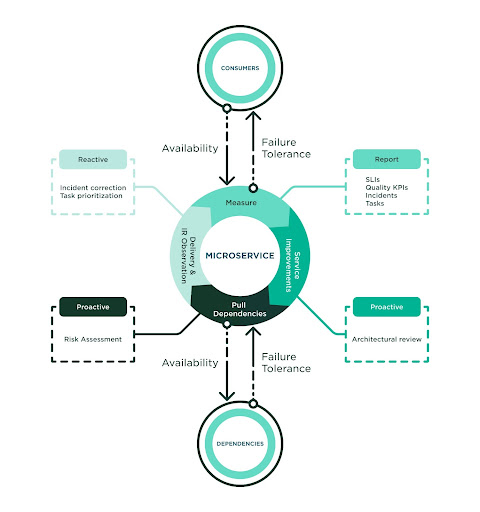
The Electricity of Appropriate Measurement
Ahead of diving deeper into metrics, there is a fast clarification to make concerning Company Level measurements.
- SLO (Services Stage Aim) is the dependability goal that our staff aims for (i.e. 99.999%).
- SLI (Service Level Indicator) is the realized trustworthiness given a timeframe (i.e. 99.975% last February).
- SLA (Service Amount Arrangement) is the dependability agreed to deliver and be anticipated by our people at a offered timeframe (i.e. 99.99% a week).
The SLI really should reflect the availability (no unhandled or missing responses), the failure tolerance (no service mistakes) and excellent attained (no unanticipated faults). Thus, we defined our SLI as the “Success Ratio” of thriving responses as opposed to the whole requests sent to a services. Productive responses are those requests that ended up dispatched in time and sort, meaning no connectivity, assistance or sudden mistakes happened.
This SLI or Results Ratio is gathered from the consumers’ stage of look at (i.e., clients). The intention is to measure the true close-to-end experience shipped to our shoppers so that we sense assured SLAs are achieved. Not performing so would create a false perception of reliability that ignores all infrastructure worries to join with our customers. Equivalent to the customer SLI, we accumulate the dependency SLI to observe any potential hazard. In practice, all dependency SLAs really should align with the assistance SLA and there is a direct dependency with them. The failure of 1 indicates the failure of all. We also keep track of and report metrics from the support itself (i.e., server) but this is not the useful resource for significant trustworthiness.
In addition to the SLIs, every single build collects high quality metrics that are documented by our CI workflow. This follow assists to strongly enforce quality gates (i.e., code coverage) and report other significant metrics, this kind of as coding typical compliance and static code investigation. This subject was previously coated in yet another article, Constructing Microservices Driven by Functionality. Diligent observance of top quality provides up when chatting about trustworthiness, because the much more we make investments in reaching outstanding scores, the far more self-assured we are that the technique will not are unsuccessful for the duration of adverse circumstances.
Our group has two dashboards. A single provides all visibility into each the Shoppers SLI and Dependencies SLI. The 2nd one particular exhibits all quality metrics. We are doing the job on merging every thing into a one dashboard, so that all of the elements we care about are consolidated and all set to be described by any provided timeframe.
Foresee Failure
Carrying out Architectural Critiques is a essential aspect of being reliable. 1st, we figure out regardless of whether redundancy is present and if the services has the usually means to endure when dependencies go down. Further than the regular replication strategies, most of our solutions utilized improved dual cache hydration methods, dual restoration tactics (this kind of as failover neighborhood queues), or details decline methods (such as transactional aid). These subjects are intensive ample to warrant a different blog entry, but in the end the finest recommendation is to carry out strategies that think about catastrophe situations and lower any efficiency penalty.
Another essential element to anticipate is just about anything that could improve connectivity. That indicates being intense about lower latency for clientele and getting ready them for pretty significant targeted traffic working with cache-regulate techniques, sidecars and performant insurance policies for timeouts, circuit breakers and retries. These techniques use to any consumer including caches, retailers, queues and interdependent clientele in HTTP and gRPC. It also means strengthening nutritious alerts from the products and services and understanding that wellbeing checks engage in an crucial function in all container orchestration. Most of our products and services do superior alerts for degradation as component of the wellness verify comments and verify all critical elements are functional ahead of sending healthful alerts.
Breaking down products and services into critical and non-critical items has established beneficial for focusing on the operation that matters the most. We applied to have admin-only endpoints in the exact same company, and while they were being not made use of often they impacted the in general latency metrics. Transferring them to their personal services impacted every single metric in a good direction.
Dependency Chance Evaluation is an important device to recognize likely complications with dependencies. This signifies we recognize dependencies with very low SLI and question for SLA alignment. Individuals dependencies need special awareness for the duration of integration methods so we commit extra time to benchmark and check if the new dependencies are mature more than enough for our strategies. A person fantastic instance is the early adoption we had for the Roblox Storage-as-a-Company. The integration with this services necessary submitting bug tickets and periodic sync conferences to communicate findings and suggestions. All of this function takes advantage of the “reliability” tag so we can swiftly recognize its supply and priorities. Characterization transpired normally till we experienced the self-assurance that the new dependency was prepared for us. This additional function served to pull the dependency to the demanded degree of reliability we expect to supply acting with each other for a common aim.
Provide Structure to Chaos
It is under no circumstances desirable to have incidents. But when they materialize, there is meaningful data to accumulate and find out from in get to be additional trustworthy. Our workforce has a crew incident report that is produced above and outside of the common enterprise-extensive report, so we concentration on all incidents regardless of the scale of their influence. We contact out the root cause and prioritize all function to mitigate it in the potential. As component of this report, we call in other teams to repair dependency incidents with significant priority, observe up with proper resolution, retrospect and search for styles that may well use to us.
The staff provides a Month to month Dependability Report for every Company that features all the SLIs stated here, any tickets we have opened for the reason that of reliability and any probable incidents associated with the services. We are so applied to generating these studies that the following normal step is to automate their extraction. Performing this periodic action is critical, and it is a reminder that trustworthiness is regularly getting tracked and considered in our improvement.

Our instrumentation involves custom made metrics and improved alerts so that we are paged as shortly as doable when known and predicted problems come about. All alerts, like wrong positives, are reviewed every single week. At this stage, polishing all documentation is critical so our customers know what to assume when alerts bring about and when errors arise, and then all people knows what to do (e.g., playbooks and integration recommendations are aligned and up to date normally).
Ultimately, the adoption of high-quality in our lifestyle is the most essential and decisive variable in reaching larger reliability. We can observe how these practices used to our day-to-working day do the job are currently spending off. Our group is obsessed with reliability and it is our most critical achievement. We have elevated our recognition of the effect that likely defects could have and when they could be released. Solutions that implemented these practices have constantly achieved their SLOs and SLAs. The dependability studies that help us keep track of all the function we have been executing are a testomony to the perform our crew has performed, and stand as a must have classes to inform and affect other groups. This is how the dependability lifestyle touches all parts of our platform.
The highway to higher reliability is not an straightforward 1, but it is needed if you want to establish a dependable platform that reimagines how men and women arrive jointly.
Alberto is a Principal Software package Engineer on the Account Identity staff at Roblox. He’s been in the activity industry a very long time, with credits on quite a few AAA activity titles and social media platforms with a robust aim on remarkably scalable architectures. Now he’s helping Roblox achieve advancement and maturity by applying best progress methods.
[ad_2]
Resource url

")





